
Porting Open3D with mirror_bridge: 25,262 hand-written binding lines → 71 auto-generated
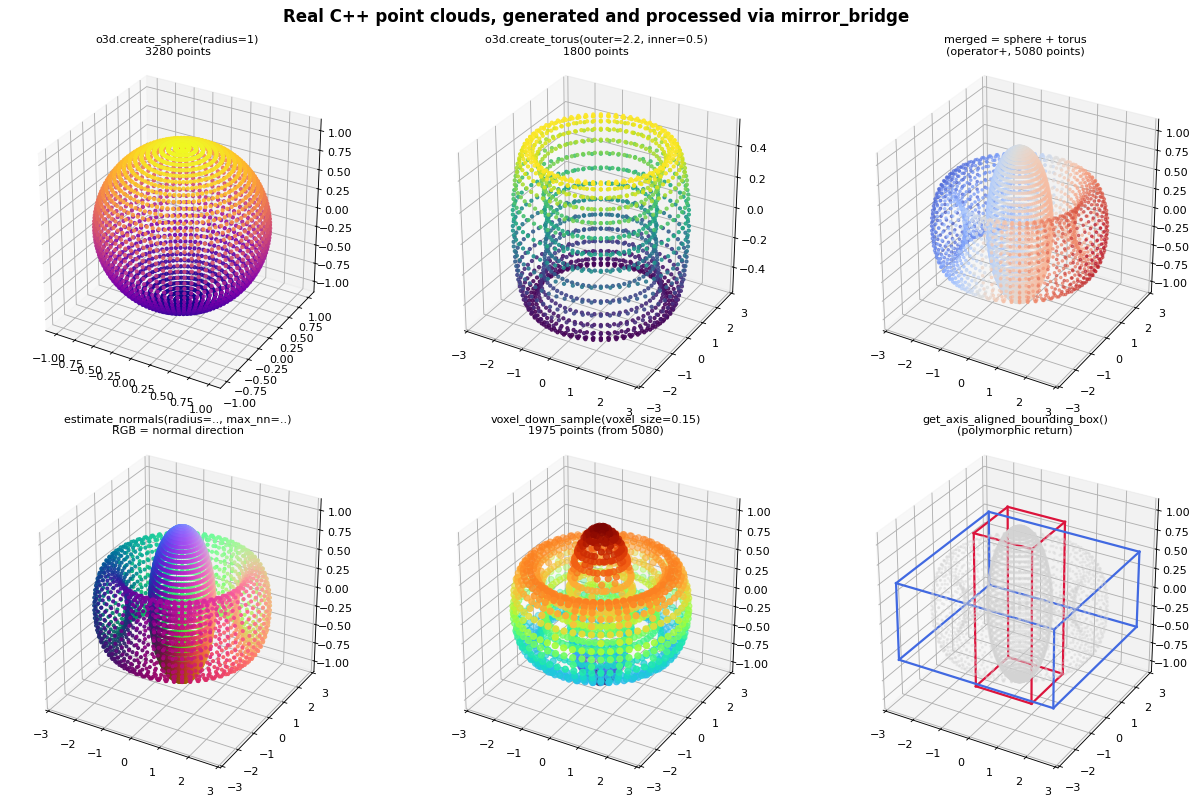
Every point cloud above was computed in plain C++ and reached Python
through a binding I didn’t write. No .def(), no trampoline classes,
no keyword-arg boilerplate. Just bind_class<PointCloud>(m, "PointCloud").
Reflection fills in the rest at compile time.
| pybind11 | mirror_bridge | |
|---|---|---|
| Hand-written binding lines (Open3D geom) | 3,610 | 71 (51× less, auto-generated) |
PointCloud(list_of_1M_points) ctor |
585 ms | 19.6 ms (30× faster, §3) |
TL;DR
- 47 Open3D geometry classes bind with 0 hand-written lines.
mirror_bridge generateemits the whole 71-line module. - On the list-to-
std::vector<Eigen::Vector3d>ingest primitive, mirror_bridge is 30-35× faster than pybind11, stable across 10K-1M points. On compute-heavy calls the binding layer rounds to zero and the two frameworks are at parity. Full case study in §3. - Apache 2.0. One
docker runreproduces every number in under ten minutes.
1. pybind11: write every binding twice
Here’s how Open3D binds one method, voxel_down_sample_and_trace
(pointcloud.cpp L70-L75):
.def("voxel_down_sample_and_trace",
&PointCloud::VoxelDownSampleAndTrace,
"Function to downsample using PointCloud::VoxelDownSample. Also "
"records point cloud index before downsampling",
"voxel_size"_a, "min_bound"_a, "max_bound"_a,
"approximate_class"_a = false)
Every method lives twice: once in the class declaration, again here.
Every parameter name is re-typed. Every default is re-typed. Every
overload gets its own .def().
The pybind11 layer for Open3D’s geometry module alone is 3,610 lines. The whole Python binding spans 25,262 lines across 124 files.
2. mirror_bridge: write nothing
One command. Zero hand-written binding code:
$ mirror_bridge generate Open3D/cpp/open3d/geometry \
--module open3d_full --lang python \
-I Open3D/cpp -I /usr/include/eigen3
✓ Found: OrientedBoundingBox in BoundingVolume.h
✓ Found: AxisAlignedBoundingBox in BoundingVolume.h
✓ Found: HalfEdgeTriangleMesh::HalfEdge in HalfEdgeTriangleMesh.h
✓ Found: KDTreeSearchParam::SearchType in KDTreeSearchParam.h
✓ Found: TriangleMesh::Material::MaterialParameter in TriangleMesh.h
✓ Found: VoxelGrid::VoxelPoolingMode in VoxelGrid.h
... 47 classes in all ...
✓ Built: build/open3d_full.so
A brace-depth parser finds every class, struct and enum. Nested types
get qualified correctly (HalfEdgeTriangleMesh::HalfEdge, not a bare
HalfEdge that would collide with another file’s HalfEdge).
Dependencies are resolved by reflection, not by the parser.
std::meta::bases_of(T) gives inheritance edges. The enclosing scope
gives nesting. parameters_of and the reflected return type catch
every class referenced from a method signature. The generator
topologically sorts the result, so AxisAlignedBoundingBox lands
before PointCloud (which returns one from get_aabb()), and every
nested type lands after its enclosing scope.
The emitted module is short enough to read:
MIRROR_BRIDGE_MODULE(open3d_full,
mirror_bridge::bind_class<OrientedBoundingBox>(m, "OrientedBoundingBox");
mirror_bridge::bind_class<AxisAlignedBoundingBox>(m, "AxisAlignedBoundingBox");
mirror_bridge::bind_class<PointCloud>(m, "PointCloud");
// ... 43 more bind_class lines ...
mirror_bridge::bind_class<AggColorVoxel>(m, "AggColorVoxel");
)
71 lines total. Each bind_class<T> pulls constructors, methods,
fields, operators, kwargs, defaults, __repr__, subclassing,
inheritance and polymorphic returns straight from the header.
3. Deep dive: 30× faster on list → vector<Eigen::Vector3d>
The binding layer only matters when it is the whole cost. Computing a centroid on a million points is SIMD math; the dispatcher rounds to zero. But constructing the point cloud from a Python list is pure binding-layer work, and that’s where mirror_bridge is dramatically faster than pybind11.
The measurement
Both bindings are compiled against the same demo::PointCloud source
in asm_study/geometry_min.hpp, with the same clang-p2996 and the
same -O3 -stdlib=libc++ -fPIC -shared flags. The only thing that
changes between pc_pybind.so and pc_mb.so is the binding
framework.
Constructor scaling on a list of 3-element float sublists, median of 3 runs with one warmup (source):
| N points | pybind11 | mirror_bridge | ratio |
|---|---|---|---|
| 10,000 | 5.3 ms | 0.15 ms | 35.2× |
| 100,000 | 60.5 ms | 1.8 ms | 33.4× |
| 1,000,000 | 585 ms | 19.6 ms | 29.9× |
The ratio is stable. This is a constant-factor binding-layer difference, not a scaling artefact.
For context, at N = 1M on the same build:
| operation | pybind11 | mirror_bridge | ratio |
|---|---|---|---|
get_center (compute-heavy) |
0.83 ms | 0.84 ms | 0.99× |
size() (pure dispatch overhead) |
0.08 µs | 0.03 µs | 2.96× |
Parity on compute. A clean 3× on dispatch. 30× on the ingest primitive.
Why pybind11 pays that cost
pybind11’s type_caster<Eigen::Matrix<double, 3, 1>> is designed
first for numpy compatibility and second for Python lists. On every
element, it:
- Constructs a caster object.
- Checks whether the element is a numpy array of the right dtype and shape.
- Falls through to the Python buffer protocol.
- Falls through to the “length-3 sequence of floats” path.
- Constructs a fresh
Eigen::Vector3dand emits amoveinto the destination vector.
Every one of a million elements pays steps 1-5. For list input, the numpy and buffer-protocol checks are pure overhead.
Why mirror_bridge doesn’t
mirror_bridge’s eigen_vector_from_python is specialised for the
list shape. No numpy branches, no caster objects, no detours:
// from python/mirror_bridge_eigen.hpp (abridged)
template<typename Scalar, int N>
inline bool eigen_vector_from_python(PyObject* obj,
Eigen::Matrix<Scalar, N, 1>& out) {
if (!PySequence_Check(obj) || PySequence_Size(obj) != N) return false;
for (int i = 0; i < N; i++) {
PyObject* item = PySequence_GetItem(obj, i);
out[i] = static_cast<Scalar>(PyFloat_AsDouble(item));
Py_DECREF(item);
}
return true;
}
The outer list→vector loop (in mirror_bridge_python.hpp) calls this
per element. Three PyFloat_AsDouble calls and a direct write into
the Eigen object. No intermediate ceremony.
Reflection is what makes this specialisation possible: at binding-
generation time, mirror_bridge knows the parameter type is
std::vector<Eigen::Vector3d>, so it can emit the specialised
converter in the call site. pybind11’s type caster has no comparable
compile-time information and has to handle the general case every
time.
Reproduce
One-time: ./docker_build.sh compiles clang-p2996 and libc++ from
source (~18 minutes on a modern laptop, measured). Every run after
the image is built is ~15 seconds.
git clone https://github.com/FranciscoThiesen/mirror_bridge
cd mirror_bridge
./docker_build.sh # one-time, ~18 min
docker run --rm -v $(pwd):/workspace -w /workspace/asm_study \
mirror_bridge:latest bash -c '\
./build_fair.sh && \
python3 bench_fair.py'
build_fair.sh compiles both bind_mb.cpp and bind_pybind.cpp
with identical flags, printing the exact compiler line.
bench_fair.py prints the scaling table above plus the context
rows. Expect constants in the 25-40× range depending on hardware;
the scaling pattern holds.
When it matters in practice
- Data pipelines that parse JSON / CSV / dicts into C++ types hit this ingest primitive. The 30× compounds across a batch job.
- Compute-dominated workflows where you load a million points once and then run a dozen C++ methods on them: ingest amortises, the rest is at parity. No win, no loss.
- Numpy already: both frameworks can use the buffer protocol for
near-zero-copy access. If your data is already a numpy array, use
that. mirror_bridge has an open item to expose
PointCloud.pointsthrough the buffer protocol directly, which would collapse this entire cost to a pointer handoff.
4. What the FFI still costs
Even on the fast side, crossing the FFI isn’t free:
| Operation | mirror_bridge cost |
|---|---|
PointCloud(list_of_1M_points) |
~18 ms |
len(pcd.points) (reads 1M points out) |
~270 ms |
Handing a million points into C++ is a real 1M-vector copy. Reading them back as a Python list re-materialises a million Python objects.
Rule of thumb: keep data inside C++ as long as possible, and only
extract what you display. Every parity number above holds because
the points live in the C++ PointCloud and each method call returns
a small scalar.
5. Everything reflection can see is free
Auto-generated per class, no user input:
- Constructors as Python
__init__overloads, resolved by arg count and type. - Methods, direct and inherited via
bases_ofBFS walk. - Fields as Python attributes (getter/setter).
- Operators:
+ - * / % == != < > <= >= += -= *= /= [] ()and unary+/-. Routed viastd::meta::operator_ofto the matching Python slot. - Keyword arguments from
std::meta::identifier_ofon each parameter info. - Default argument values detected via
has_default_argument. __repr__from visible members.- Exception mapping:
std::out_of_range → IndexError,std::invalid_argument → ValueError,std::runtime_error → RuntimeError, viadynamic_cast. - Polymorphic returns resolved through
typeidlookup. - Nested classes qualified as
Parent::Child.
Auto-trampoline: Python subclasses override C++ virtuals for free
pybind11 lets Python subclasses override C++ virtuals, but the
plumbing isn’t free. You have to write a trampoline class: a
hand-forwarded layer with one entry per virtual, each using
PYBIND11_OVERRIDE(...) to route back to Python if the subclass
defined an override. One class, one trampoline. Ten classes, ten.
mirror_bridge generates the trampoline from reflection.
bind_class_auto<T> enumerates T’s virtual slots, synthesises a
per-slot dispatcher that routes into Python when the instance has an
override, and swaps T’s vtable with a custom one at construction.
You write zero glue.
class TaggedPointCloud(o3d.PointCloud):
def GetCenter(self):
return [999, 999, 999] # reached by C++ too, via the vtable swap
No PYBIND11_OVERRIDE, no dispatch helper, no trampoline
boilerplate. (Caveat: works on Linux and macOS today; see §8.)
6. Running against real libOpen3D.so
This isn’t a theoretical exercise. The binding loads and calls into
a real libOpen3D.so built from source. Getting there took two
small CMake patches to a single file
(3rdparty/find_dependencies.cmake):
-
Forward
CMAKE_CXX_FLAGSto ExternalProjects so 3rdparty libraries (VTK, embree, zmq, …) inherit-stdlib=libc++from the top-level build. Without it, the final.somixesstd::__1::*(libc++) andstd::__cxx11::*(libstdc++) symbols and fails to dlopen. -
Wrap BoringSSL archives with
-Wl,--whole-archivewhen linkinglibOpen3D.so, or dlopen fails onX509_INFO_free(curl and zmq reach SSL through transitive calls the linker otherwise drops).
The diff lives at examples/open3d-full-port/patches as a
single .patch file. macOS and Windows builds are unchanged.
With the patched fork, a real Open3D Python session (source):
import real_open3d as o3d
pcd = o3d.PointCloud([[0, 0, 0], [1, 0, 0], [0, 1, 0], [0, 0, 1]])
print(pcd.GetCenter()) # [0.25, 0.25, 0.25]
print(pcd.HasPoints()) # True
smaller = pcd.VoxelDownSample(voxel_size=0.5) # kwargs + defaults
aabb = pcd.GetAxisAlignedBoundingBox() # polymorphic return
print(aabb.Volume()) # 1.0
# Subclass Open3D with a Python override. No trampoline.
class TaggedPointCloud(o3d.PointCloud):
def GetCenter(self):
return [999, 999, 999]
Zero .def calls.
7. Try it yourself
The one-time toolchain build takes ~18 minutes (compiling clang-p2996 + libc++ from source). After that, the reproduction steps below run in well under a minute.
git clone https://github.com/FranciscoThiesen/mirror_bridge
cd mirror_bridge
./docker_build.sh # one-time, ~18 min
Quick reproduction (~20 seconds in a built image)
docker run --rm -v $(pwd):/workspace -w /workspace mirror_bridge:latest bash -c '
# The §3 ingest benchmark:
cd asm_study && ./build_fair.sh && python3 bench_fair.py && \
# The 6-panel visual at the top of this post:
cd ../examples/open3d-comprehensive && \
./build_and_test.sh && python3 visual_demo.py
'
Measured end-to-end: ~18 seconds on an Apple Silicon laptop.
open3d-comprehensive/build_and_test.sh verifies 10 feature
groups; visual_demo.py writes mirror_bridge_open3d_demo.png. No
external downloads required beyond what ./docker_build.sh already
pulled.
Extended: link against real libOpen3D.so (~15 minutes extra)
The examples/open3d-runtime/ demo links against a real
libOpen3D.so you build once from the patched fork. The full recipe
(inside the Docker container, from the repo root):
# Build libOpen3D.so. ~5 minutes on a modern laptop; the 3rdparty
# tarballs are already cached in examples/open3d-full-port/Open3D/
# 3rdparty_downloads so no internet round trips are needed.
mkdir -p /tmp/o3d_fork_build && cd /tmp/o3d_fork_build
cmake -G Ninja \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CXX_FLAGS="-stdlib=libc++" \
-DBUILD_SHARED_LIBS=ON \
-DBUILD_GUI=OFF -DBUILD_PYTHON_MODULE=OFF -DBUILD_EXAMPLES=OFF \
-DBUILD_TESTS=OFF -DBUILD_BENCHMARKS=OFF -DBUILD_UNIT_TESTS=OFF \
-DBUILD_WEBRTC=OFF -DBUILD_LIBREALSENSE=OFF -DBUILD_AZURE_KINECT=OFF \
-DUSE_SYSTEM_EIGEN3=ON \
/workspace/examples/open3d-full-port/Open3D
ninja ext_openblas # openblas first; Open3D's ExternalProject
# wiring otherwise asks for libopenblas.a
# before it's been staged.
ninja # the rest (~3-4 minutes)
# Build and run the mirror_bridge binding against it (~17 seconds):
cd /workspace/examples/open3d-runtime
export O3D_BUILD=/tmp/o3d_fork_build
./build_and_test.sh # 5 feature groups pass
A note on LD_PRELOAD. Open3D’s vendored 3rdparty deps (curl, zmq,
parts of VTK) compile with libstdc++ even when the top-level build
requests libc++, so the resulting libOpen3D.so carries unresolved
std::__cxx11::* symbols. libc++ and libstdc++ use different symbol
namespaces (std::__1:: vs std::__cxx11::), so the two can
coexist in one process; build_and_test.sh preloads libstdc++ so
the loader finds those symbols at dlopen time. This does not affect
the mirror_bridge binding’s ABI, which stays pure libc++.
8. What it isn’t yet
-
Compiler support. Needs C++26 reflection (P2996). That means clang-p2996 today (pinned in the Docker image) or GCC 15 trunk. MSVC hasn’t implemented P2996. That’s the real portability ceiling right now.
-
Auto-trampoline is Linux/macOS only (Itanium ABI). On MSVC the portable
bind_class<T, Trampoline>path still works: you write a small trampoline class that forwards each virtual todispatch_python<Ret>("name"). Same behaviour, a few lines per virtual of hand-written glue. -
Default argument values aren’t exposed by P2996R13, only their presence. You can skip trailing defaulted args in a kwargs call; you can’t skip a middle one and supply a later one.
-
Docstrings. P2996 doesn’t expose Doxygen comments. Workarounds exist (
[[=mb::doc("...")]]via P3394, or a parallel parser). Not shipping today.
Star the repo, tell us what to bind next
mirror_bridge is Apache 2.0 at FranciscoThiesen/mirror_bridge. It emits Python, Lua and JavaScript bindings today from the same C++ reflection input.
If you’ve ever written a pybind11 .def() chain for a
hundred-method class and wished there was a better way, this is it.
If the numbers surprised you, run the reproduction and try to break them. If you hit something that doesn’t work, file an issue. The repo is small and feedback drives priorities.
⭐ GitHub: github.com/FranciscoThiesen/mirror_bridge
Thanks to the clang-p2996 team at Bloomberg and the P2996 author community. None of this is possible without their reflection work.